版权声明:本文由文智原创文章,转载请注明出处:
文章原文链接:来源:腾云阁
一.文本聚类概述
文本聚类是文本处理领域的一个重要应用,其主要目标是将给定的数据按照一定的相似性原则划分为不同的类别,其中同一类别内的数据相似度较大,而不同类别的数据相似度较小。聚类与分类的区别在于分类是预先知道每个类别的主题,再将数据进行划分;而聚类则并不知道聚出来的每个类别的主题具体是什么,只知道每个类别下的数据相似度较大,描述的是同一个主题。因此,文本聚类比较适合用于大数据中热点话题或事件的发现。
文智平台提供了一套文本聚类的自动化流程,它以话题或事件作为聚类的基本单位,将描述同一话题或事件的文档聚到同一类别中。用户只需要按照规定的格式上传要聚类的数据,等待一段时间后就可以获得聚类的结果。通过文本聚类用户可以挖掘出数据中的热门话题或热门事件,从而为用户对数据的分析提供重要的基础。本文下面先对文本聚类的主要算法作介绍,然后再具体介绍文智平台文本聚类系统的原理与实现。
二.文本聚类主要算法
文本聚类需要将每个文档表示成向量的形式,以方便进行相似度的计算。词袋模型(bag of words,BOW)是文本聚类里面的一种常用的文档表示形式,它将一个文档表示成一些词的集合,而忽略了这些词在原文档中出现的次序以及语法句法等要素,例如对于文本“北京空气重污染拉响黄色预警”,可以表示为词集{北京,空气,污染,黄色,预警}。通过词袋模型将文档转化为N维向量,进而构造整个文档集合的词语矩阵,就可以使用一些数值运算的聚类算法进行文本聚类。
当然,并不是所有的词都用来构建文档的词向量,可以去掉一些像a、an、the这样的出现频率很高而又无实际意义的词,这样的词没有什么类别区分能力,应作为停用词而去掉。另外,可以使用TF-IDF等方法来评估一个词对于文档的重要程度,保留对文档较为重要的词作为词向量之用。
以词袋模型为基础,将文档表示成N维向量,进而可以利用相关的聚类算法进行聚类计算。常用的文本聚类算法有层次聚类算法、划分聚类算法(例如k-means、k-medoids算法)以及基于主题模型的聚类算法(例如PLSA、LDA)等。
1.层次聚类算法
层次聚类算法是对给定的数据集进行层次的分解,直到达到某个终止条件为止。具体可以分为凝聚和分裂两种方式。凝聚是自底向上的策略,首先将每个对象作为一个类别,然后根据对象之间的相似度不断地进行合并,直到所有对象都在一个类别中或是满足某个终止条件;而分裂则与凝聚相反,用的是自顶向下的策略,它首先将所有对象都放到一个类别中,然后逐渐分裂为越来越小的类别,直到每个对象自成一个类别或是满足某个终止条件。大多数的层次聚类算法都采用凝聚的方式,这里就以凝聚的方式为例对算法进行介绍。
层次聚类算法的输入是数据集中所有对象的距离矩阵,并预先设定一个距离阈值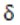 ,用于迭代的终止,算法的主要步骤如下:
,用于迭代的终止,算法的主要步骤如下:
- 将每个对象作为一类,类与类之间的距离就是它们所包含的对象之间的距离;
- 找出距离最接近的两个类,如果它们的距离小于,则将它们合并为一类;
- 重新计算新的类与所有其它旧类之间的距离;
- 重复第2步和第3步,直到所有的类无法再进行合并为止;
其中步骤3中类与类之间距离的计算方法有3种,分别为:
- Single Linkage:类间距离等于两类对象之间的最小距离,这种方法计算简便,但是容易导致两个类从大范围看是比较远的,却由于个别的点比较近而被合并的情况,而且这种情况还会不断扩散,最后造成类别比较松散;
- Complete Linkage:类间距离等于两类对象之间的最大距离,这种方法有时也不太好,容易导致两个比较近的类由于存在一些较远的点而老死不合并;
- Group-AverageLinkage:类间距离等于两类对象之间的平均距离,前面两种方法的不足都是由于只考虑了类内数据的局部情况,而缺乏整体上的考虑,取平均距离能够改善前面两种方法的不足,但是计算量相应也有所增加。
层次聚类算法的优点是计算速度较快,并且不需要指定最终聚成的类别个数,但是需要预先指定一个距离阈值作为终止条件,这个距离阈值的设定需要一定的先验知识。
2. 划分聚类算法
划分聚类算法中有代表性的算法是k-means算法和k-medoids算法,这里以较为常用的k-means算法为代表进行介绍。
k-means算法是基于距离的聚类算法,输入是数据集中所有文档的词向量矩阵,需要预先指定最终聚成的类别个数k,并且还需要指定算法迭代终止的条件,这可以通过指定迭代的次数或是指定前后两次迭代中k个质心距离变化的总和小于一定阈值作为算法迭代终止的条件。k-means算法的主要步骤如下:
- 初始条件下,随机选取k个对象作为初始的质心;
- 计算每个对象到k个质心的距离,将对象归到距离最近的质心的类中;
- 重新计算各个类的质心,取类中所有点的平均值作为该类新的质心;
- 重复第2步和第3步,直到达到指定的迭代次数或是新旧质心距离变化之和小于指定阈值;
k-means算法需要预先指定聚成类别的数目k,这需要一定的先验知识,而且算法迭代终止条件的设定也是要根据一定的经验。另外,算法初始质心的选取会影响到最终的聚类结果,有不少文献都在研究优化k-means算法初始质心的选取。
3.基于主题模型的聚类算法
基于主题模型的聚类算法是假定数据的分布是符合一系列的概率分布,用概率分布模型去对数据进行聚类,而不是像前面的层次聚类和划分聚类那样基于距离来进行聚类。因此,模型的好坏就直接决定了聚类效果的好坏。目前比较常用的基于主题模型的聚类算法有LDA和PLSA等,其中LDA是PLSA的一个“升级”,它在PLSA的基础上加了Dirichlet先验分布,相比PLSA不容易产生过拟合现象,LDA是目前较为流行的用于聚类的主题模型,这里以LDA为代表介绍基于主题模型的聚类算法。
LDA(Latent Dirichlet Allocation,隐含狄利克雷分配),是一种三层贝叶斯概率模型,它由文档层、主题层和词层构成。LDA对三层结构作了如下的假设:
- 整个文档集合中存在k个相互独立的主题;
- 每一个主题是词上的多项分布;
- 每一个文档由k个主题随机混合组成;
- 每一个文档是k个主题上的多项分布;
- 每一个文档的主题概率分布的先验分布是Dirichlet分布;
- 每一个主题中词的概率分布的先验分布是Dirichlet分布;
LDA模型的训练过程是一个无监督学习过程,模型的生成过程是一个模拟文档生成的过程,文档中的一个词首先是根据一定的主题概率分布抽取出一个主题,然后是从这个主题中以一定的概率分布抽取出一个词,如此重复,直到生成文档中所有的词。LDA在模型中以Dirichlet分布为基本假设,其生成过程如图2所示。
 图2 LDA的模型生成过程
图2 LDA的模型生成过程 在实际的应用中,可以通过Gibbs Sampling来对给定的文档集合进行LDA训练。首先是用户需要设定生成的模型的主题个数k,然后是对给定的文档进行分词,去掉停用词,获得文档的词袋模型,作为训练的输入。
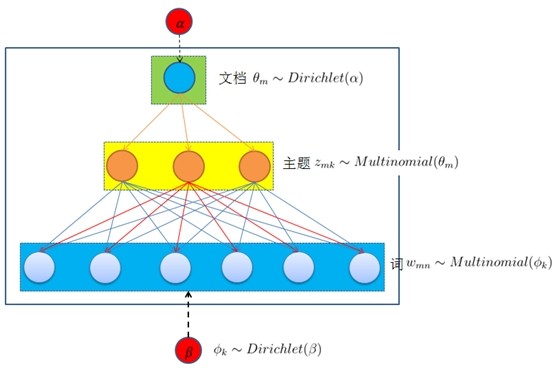
 图3 使用Gibbs Sampling的LDA训练过程
图3 使用Gibbs Sampling的LDA训练过程 LDA中隐含的变量包括文档的主题分布Θ、主题的词分布Φ以及词所属的主题Z。Gibbs Sampling通过不断的抽样与迭代,推算出这些隐含变量。如图3所示,Gibbs Sampling在初始时随机给每个词分配主题z(0),然后统计每个主题z下出现词t的数量以及每个文档m下出现主题z中的词的数量,再计算 ,即排除当前词的主题分布,根据其它词的主题分布来估计当前词分配到各个主题的概率。当得到当前词属于所有主题的概率分布后,再根据这一概率分布为该词抽样一个新的主题z(1)。然后用同样的方法不断更新下一个词的主题,直到文档的主题分布Θ和主题的词分布Φ收敛或是达到预定的迭代次数为止。最终输出所有的隐含变量,每个词所属的主题也能够得到。根据每个词所属的主题分布,就可以进一步计算出每个文档所属的主题及其概率,这就是LDA聚类的结果。
,即排除当前词的主题分布,根据其它词的主题分布来估计当前词分配到各个主题的概率。当得到当前词属于所有主题的概率分布后,再根据这一概率分布为该词抽样一个新的主题z(1)。然后用同样的方法不断更新下一个词的主题,直到文档的主题分布Θ和主题的词分布Φ收敛或是达到预定的迭代次数为止。最终输出所有的隐含变量,每个词所属的主题也能够得到。根据每个词所属的主题分布,就可以进一步计算出每个文档所属的主题及其概率,这就是LDA聚类的结果。
三.文本聚类系统的实现
在上一节中我们介绍了常用的文本聚类算法,其中层次聚类算法和k-means算法等都是基于距离的聚类算法,而LDA则是使用概率分布模型来进行聚类。基于距离的聚类算法的优点是速度比较快,但是它们都是通过两个文档共同出现的词的多少来衡量文档的相似性,而缺乏在语义方面的考虑。相反,LDA等基于模型的聚类算法能够通过文本中词的共现特征来发现其中隐含的语义结构,对“一词多义”和“一义多词”的现象都能够建模,并在聚类结果中得到体现。“一词多义”就例如“苹果”一词,它可能是指水果,可能是指手机,也可能是指公司,LDA能够将其分配到不同的主题中;而“一义多词”就例如众多的同义词,它们虽然在文本上并不相似,但是在语义上是相似的,LDA能够将它们聚集到一起。正是由于LDA在语义分析方面的优势,我们文智平台的聚类系统使用LDA来进行文本聚类。但是LDA在训练中会比较耗时,单机情况下300万的文档数据训练需要100多个小时,这是不能接受的,因此需要对LDA做并行化计算。
1.基于Spark的LDA并行化计算
Spark是继Hadoop之后新一代的大数据并行计算框架,是目前大数据分析的利器。相比于传统的Hadoop MapReduce,Spark将计算时的中间结果写到内存中,而不是写磁盘,而且在同一个任务中可以重复利用task对象,而无需重新创建,这使得Spark非常适合应用于类似LDA这样的需要反复迭代的算法中。
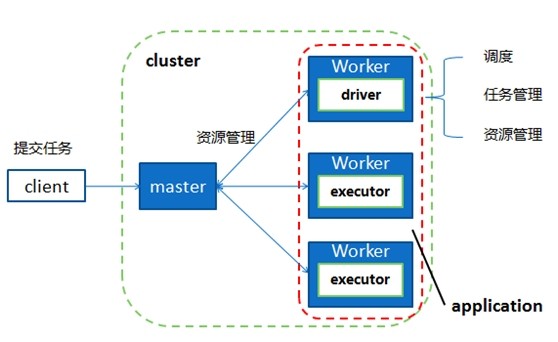 图4 Spark任务执行总体框架
图4 Spark任务执行总体框架 Spark在任务的执行上也是跟Hadoop类似,通过一定的任务管理器和调度器将任务分配给各个节点来并行化执行,从而能够取得比单机环境下快数十倍的计算效率,如图4所示。对于LDA,其训练过程主要是Gibbs Sampling,目前已经有对LDA中Gibbs Sampling进行并行化的方法。具体地说,就是将训练数据分成多份,分配给每个节点进行独立的并行化训练,训练完成后再更新全局模型,然后再根据全局模型进行下一轮的迭代训练,如此重复,直到任务结束,如图5所示。
 图5 LDA并行化计算
图5 LDA并行化计算 在Spark中实现上述的LDA并行化流程,可以极大地提升LDA的计算效率,训练300万的文档数据由原来的需要100多个小时减少到只需5到6个小时。
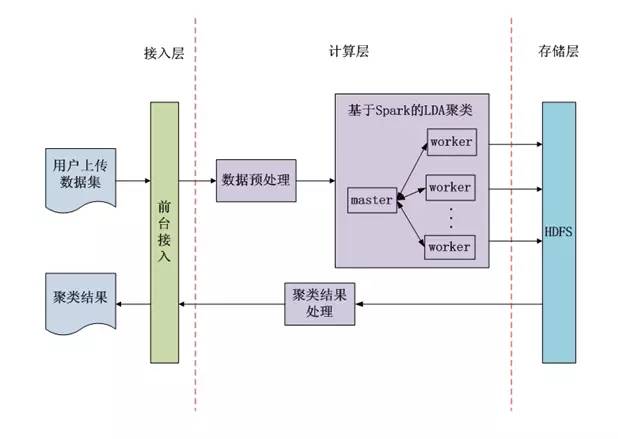
2.文本聚类系统整体架构
文智平台文本聚类系统的整体架构如图6所示,主要分为接入层、计算层和存储层三层。用户通过前台页面按照规定的格式上传数据文件,然后在计算层首先会对数据进行预处理,去除无效数据,接着使用Spark对数据进行LDA聚类,这是一个反复迭代的过程。用户可以指定生成的主题个数以及迭代的最大次数,如果用户不指定我们也会有默认值。LDA聚类得到的结果再经过简单的统计和排序整理就能够生成数据中的热门话题,热门话题和聚类结果最后会返回给用户。整个计算层的操作都是无需用户参与的,用户只需要上传数据文件,然后等待一段时间后就可以获得文本聚类的结果。
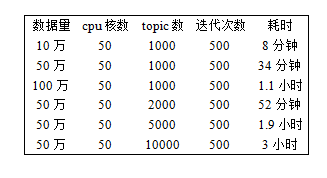
文智平台基于Spark的LDA聚类系统能够快速而有效地对数据进行聚类,聚类的平均准确率达到80%以上,而且经过对Spark平台的不断优化,聚类的效率也在不断提高,表1中所示的是系统目前聚类的性能情况,后续还会在性能方面对系统不断进行优化。
表1 基于Spark的LDA聚类系统性能情况
四.总结
文智平台文本聚类系统使用Spark对文本数据进行LDA聚类,可以从语义的层面上挖掘出用户数据中的热门话题。系统的应用范围非常广泛,可以应用于各类文本数据,尤其是对海量社交数据的分析非常有效。这一整套使用LDA进行文本聚类的机制目前已经较为成熟,已经在为公司内的一些部门提供文本聚类服务,我们期待今后系统能得到更为广泛的应用。